
The story for this starts with wanting to figure out how a student can get from point A in skillset to point B in skillset (their desired ambition) - given an educational ecosystem that provides certain opportunities. And we did realize it, atleast for 3000+ students in my undergraduate college.
I ran Coursepanel for a year and we built several cool things in this journey. I'll keep this blog fairly technical but also throw in certain snippets about entrepreneurship and lessons learnt along the way. Most of this blog is going to be about the technical implementation of this project. I have mentioned my learnings as an entrepreneur in the end.
To read the story of the early days and launch, checkout - here

Technical Deep-dive
Understanding Natural Language Processing and Vector Embeddings
Natural Language Processing (NLP) is a field at the intersection of computer science, artificial intelligence, and linguistics. It involves programming computers to effectively process large amounts of natural language data. As part of NLP, Large Language Models (LLMs) like GPT-3, developed by OpenAI, are designed to generate human-like text based on the inputs they receive. They are trained on a diverse range of internet text and can generate contextually relevant text.
However, they do not know specific documents or sources they were trained on and don't have the capability to access or retrieve specific documents or databases during the generation process. Their strength lies in understanding and generating text that closely resembles human-like responses, thus forming a key part of systems like CourseGPT.
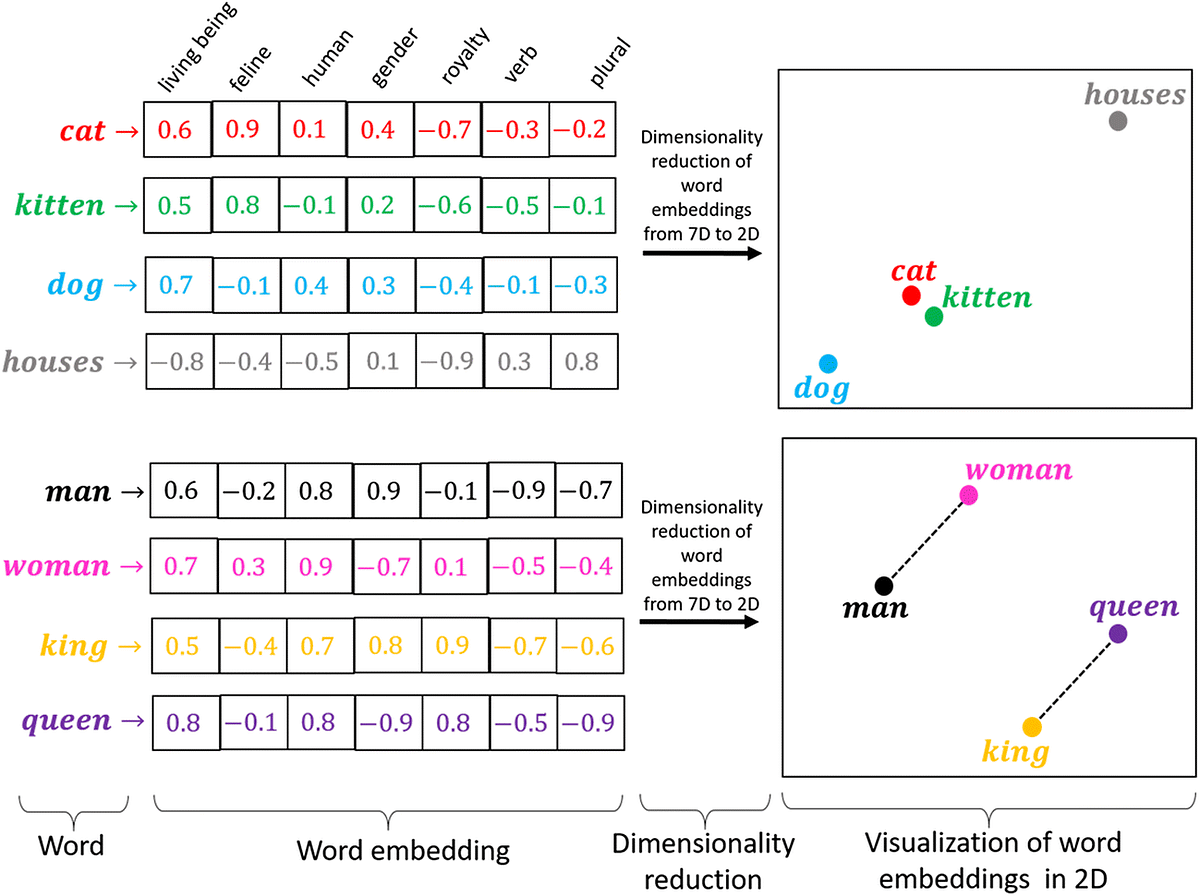
Vector embeddings are another crucial component of such systems. In the realm of machine learning, embeddings are a way to convert categorical variables into continuous vectors so as to feed them into a model. They can be used to capture the semantics of words in a language, relationships between items, and even user behavior in an application.

Basic demo of how words are converted into vector embeddings (source)
These embeddings, when stored in a vector database, form the basis of effective search and recommendation systems.
Building a vector database using a knowledge graph
For the purpose of this project, based on the previous training data, we turned our knowledge graph (aka “skillmap”) into a vector database for storing entries and answering queries related to academic data. This was done in 4 steps:
- Creating a Knowledge Graph in Neo4j: The first step involved modeling our data as a graph and storing it in Neo4j. Our nodes represent entities such as NPTEL courses, books, departments, etc., and relationships represented the connections between these entities
- Generating Vector Embeddings: The next step involved generating vector embeddings from our graph. These embeddings are a form of representation that captures the semantic meaning and relationships of your data in the form of vectors in a high-dimensional space. There are several techniques to generate graph embeddings, like Node2Vec, GraphSAGE, etc. This project used the Node2Vec library in Python to achieve the same. We ran Node2Vec algorithms on our Neo4j graph to generate node and relationship embeddings.
- Store Vector Embeddings: The generated embeddings then needed to be stored for future use. Typically, we’d want a database that is optimized for storing and querying high-dimensional vectors. You could use a vector database like Pinecone, Faiss, or even Elasticsearch with a vector plugin for this purpose.
- Querying the Vector Database: The final part involved using these vector embeddings to make our application smarter. For example, we could now perform operations like semantic search, recommendations, or similarity checks by comparing vectors. This involved querying our vector database for the nearest vectors to a given input vector, which gave us the most semantically similar entities to our query.
Scoping NPTEL data into the Vector Database and building a chatbot
To create a system like CourseGPT, we first need to load the relevant data into the vector database. Let's assume we have course data from NPTEL in a CSV format. This data can be processed and converted into vector embeddings using various techniques like Word2Vec, GloVe, or even using transformers-based models. These vector representations can then be loaded into the vector database, which allows us to perform efficient similarity search operations.
The vector database enables us to compare the query vector (which can be a representation of a user's query or a specific course interest) with all vectors in our database, and retrieves the most similar entries. These entries represent courses that are most relevant to the user's query.
Once the entries are returned, we need to translate these course vectors back into a human-readable form. This is where LLMs like GPT-3 come into play. These models can generate contextually relevant, human-like text based on the returned entries. The generated text can be as simple as a course name and description, or as complex as a detailed career path recommendation.
In this way, the synergy of NLP, LLMs, and vector databases leads to the development of an effective system like CourseGPT. Such a system can revolutionize the way we approach professional upskilling and corporate training by providing personalized, contextual, and interactive learning experiences.
The journey in a nutshell
The development and evolution of CourseGPT, spread over a 12-month period, could've been a significant step forward in the application of advanced technologies such as AI, Natural Language Processing (NLP), and Knowledge Graphs to the critical area of professional upskilling and corporate training.
The journey began with understanding the problem domain, setting the objectives and scope, and constructing the methodology flowchart. The decision to pick a test sandbox environment of similar nature proved instrumental in aligning the development of CourseGPT closely with the real-world challenges encountered in professional learning and development.
Deep dives into models of corporate training, specifically the Kirkpatrick Model, provided insights into the metrics for successful training outcomes. Skill mapping using a knowledge graph emerged as a novel and efficient approach to resolving course recommendations and facilitating an effective learning journey for the students.
Working with the NPTEL team and building a skill map for IIT Madras underscored the potential of this tool in academic environments as well. Implementing Natural Entity Recognition and NLP allowed us to extract valuable course tags and derive meaningful insights from the data.
Moreover, the research conducted at HyperVerge Academy (HVA) enabled a deeper understanding of the professional upskilling space. Facing and overcoming various challenges along the way, we succeeded in developing a competency engine and data model that significantly enriched the capabilities of CourseGPT.
Finally, CourseGPT emerged as an intelligent product, leveraging the power of Knowledge Graphs to recommend courses based on career goals, plan academic journeys, solve student doubts, and inclusively cater to diverse learners. The journey, although filled with complexities and challenges, offered valuable insights into the future of AI-enabled learning and set a foundation for ongoing research and development.
Here's the various launch videos of products that I built, just as a nostalgic flash from the past.
Why I failed to run it as a company.
With Coursepanel, we made around 35000 INR in revenue with 3000+ free users and then got stuck in a loop of developing without continuous customer interaction. I shut down Coursepanel in May 2023. I was embarassed, mentally disturbed and self-doubting when I did it. It was hard and it was like I had given up on a dream and failed myself. But picking up and moving on is the way forward. Here are a few things I learnt from this experience - these aren't novel learnings - these are the same fuckups most startup folks advise against but I did it anyway and learnt it again - at a heavy price:
- Don't do it alone. It's not that I'm doubting individual capability - it's just that context switching has a very difficult toll when you want strong velocity in both business and innovaiton. Also there's the emotional burden of doing it alone. Worst case, atleast have a friend to talk to and help sort out a lot of operations and communications
- It's best to build a shitty product with continuous customer interaction but no point of siloed building, no matter what you feel about current systems. Even asking and then building then again asking then building - i.e. an intermittent month-to-month setup might not help. Atleast talk to users each week.
- Make money from the start. It's the only way to stay afloat.
- Don't get to emotionally attached to your innovation or amazed by exciting new things you can do. Focus on the minimum that gets you paid, get it right and then expand with bolder experiments.
- It's boring and requires discipline and routine to continuously outperform other teams. You have to consistently just keep pushing. Motivation is 2/3rds of this game.
So yeah, I guess that's about it. I was very passionate, worked very hard and was heartbroken - but I guess I'm carrying forward a lot - something that classroom would have never taught me. Let's see, I'm about to do something again in the Generative AI space. This time - business first though - get the "what are people gonna pay for" right and then expand from that base thought into technical innovation and exquisite design.

{kind=link}