

Okay so this post is not actually about college ragging but majorly about Retrieval Generated Augmentation (RAG), a cool machine learning and indexing application I came across while building CloudPilot - "the copilot for cloud engineers"
What is CloudPilot? ✈️
CloudPilot was a project we built with the vision of going from idea to cloud within 10 minutes.
The goal of the project was to enable any thinker to start with a business problem, quickly to research and come up with a wholesome engineering document that had the solution approach, its architecture and performance analysis done well in under 10 minutes.
This product was built at a hackathon in under 24 hours. Let me know if there are any improvements you want me to look at.
And with that, let's dive in, into the product flow

What does a cloud engineer do?
First, let's understand how cloud architects function and come up with infrastructure solutions for a given business problem. See, as a typical cloud architect - the flow is as follows
- Step 0: - It starts with a problem statement such as a architecture for payment gateway or a data migration pipeline or a high availability server fleet setup.
- Step 1: Ask the right questions - Several times, we go back and forth with the problem statement to understand what are the exact business requirements and what are important aspects that we need to optimize for.
- Step 2: Research - With the given requirements, the standard approach is to go online, read up some blogs by cloud providers, read case studies and open source articles to get context and understand our problem statement. Here, typically a lot of time is just spent in finding the right article. Most software problems have precedents that have solved the requirement wholly or in parts. Hence, finding the right documentation for similar requirements is of paramount importance.
- Step 3: Technical Requirements - Once we have asked the right questions, we prepare a brief technical document, highlighting the most important performance expectations from the software and then start researching what kind of cloud offerings do we require. We also quantify that to what extent do we want to look at satisfying a particular goal. eg: 500 TB of storage, 80ms latency in communication, 7 0s of availability, 8GB GPUs for ML training.
- Step 4: List the building blocks - Here, we simply map each techinal requirement to an existing cloud service we can use and do a comparative analysis. If it's ML, it's gotta be Google Cloud, for availability and cost, it's gotta be AWS - that kinda thing. So we start listing cloud offerings such as EC2 (AWS), Maps API (Google Cloud) or Azure OpenAI (Microsoft Azure). We think of using these offerings as builing blocks for the entire architecture and justify why the offering is important
- Step 5: Join the blocks - Here, we join together the building blocks as services that communicate with 1 another and draw a
systems diagramthat helps to understand how the overall system works. Which part does what function and how it's role fits into the overall requirement. - Step 6: Iterate - Once an end-to-end flow is ready, we do overall Product, Engineering and Cost Analysis and then we iterate upon the design to optimize for certain aspects - make it faster, make it cheaper, increase the storage, increase the redundancy - that kind of thing. And based on that, we improve the choice of building blocks and integrating them together in 1 system
- Step 7: Templatize - Once a cloud architecture is ready, we start looking at using Cloud templates such as CloudFormation by AWS, Terraform by Hashicorp to easily just deploy the entire architecture and have a skeleton of it functional to understand performance on a practical level.
Thus, this is the overall flow of the entirety of coming up with a cloud architecture. Beautiful and methodical.
So if we were to copilotize this process we would need an AI agent who could read through all cloud architecture related blogs, docs, case-studies like an engineer and intuitively go through steps 1 to 8 and help arrive upon a solution.
And that's why we used something called Retrieval Augmented Generation (RAG) - a technique where we retrieved the right list of documents from the internet and asked our Large Language Model to generate an answer from text that it studied from these docs.
Before we segway into what we did, let's study in short - what is this "Retrieval Augmented Generation" anyways?
Retrieval Augmented Generation (RAG)

Imagine you're a chef and you're trying to create a new dish. First, you go to your pantry (which has a vast array of ingredients). This is akin to the retrieval part. You take a look at different recipes you have used in the past or a recipe book for ideas. You fetch or 'retrieve' ingredients and inspiration based on these recipes.
Next, you start to combine these ingredients together, perhaps in a way you've never done before. You might modify some of the recipes to match your taste or to make the dish unique. This is similar to the 'generation' part of the process.
Now, let's say you have some guests coming over and you know their preferences. To accommodate them, you decide to modify your new dish even further or add some garnish to make it look more appealing. This is comparable to the 'augmentation' part, where you make some tweaks to make the final result better suited for its purpose.
Bringing it back to the context of AI and natural language processing, Retrieval-Generated Augmentation is a method where you:
- 'Retrieve' relevant data or content from a large dataset (like a chef searching through the pantry or recipe books).
- 'Generate' new data or content based on this retrieved data (like a chef creating a new dish using the fetched ingredients), and then
- 'Augment' this generated content, usually by making some modifications to better suit the task at hand (like a chef adjusting the dish to suit the guests' taste).
This method is very useful for tasks that involve generating text or other types of data, especially when you want to produce content that is tailored for a specific task, purpose, or audience.
It's also a way to improve the performance of machine learning models, by providing them with a richer, more varied dataset to learn from. The richer and more varied the 'ingredients' (i.e., the data), the better the 'dish' (i.e., the model's output) can potentially be.

How we built the damn thing
Part 1: "Retrieve"
For this we would leverage the open-source documents, blogs, systems diagrams and articles by major Cloud Providers such as AWS, Google Cloud and Microsoft Azure.
We created a custom index of just these documents. Using Amazon Kendra, we indexed over 192000 such information webpages using its web-connector. Here, the major difficulty we faced was understanding which XML sitemaps did we have to index and how. Some documents were in Japanese and some were just plain irrelevant marketing content. So intelligent document structure filtering was required at this level to index the right documents for our search.
Thus, this helped us to get the best documents to pull in for a given query. For example the queries below.
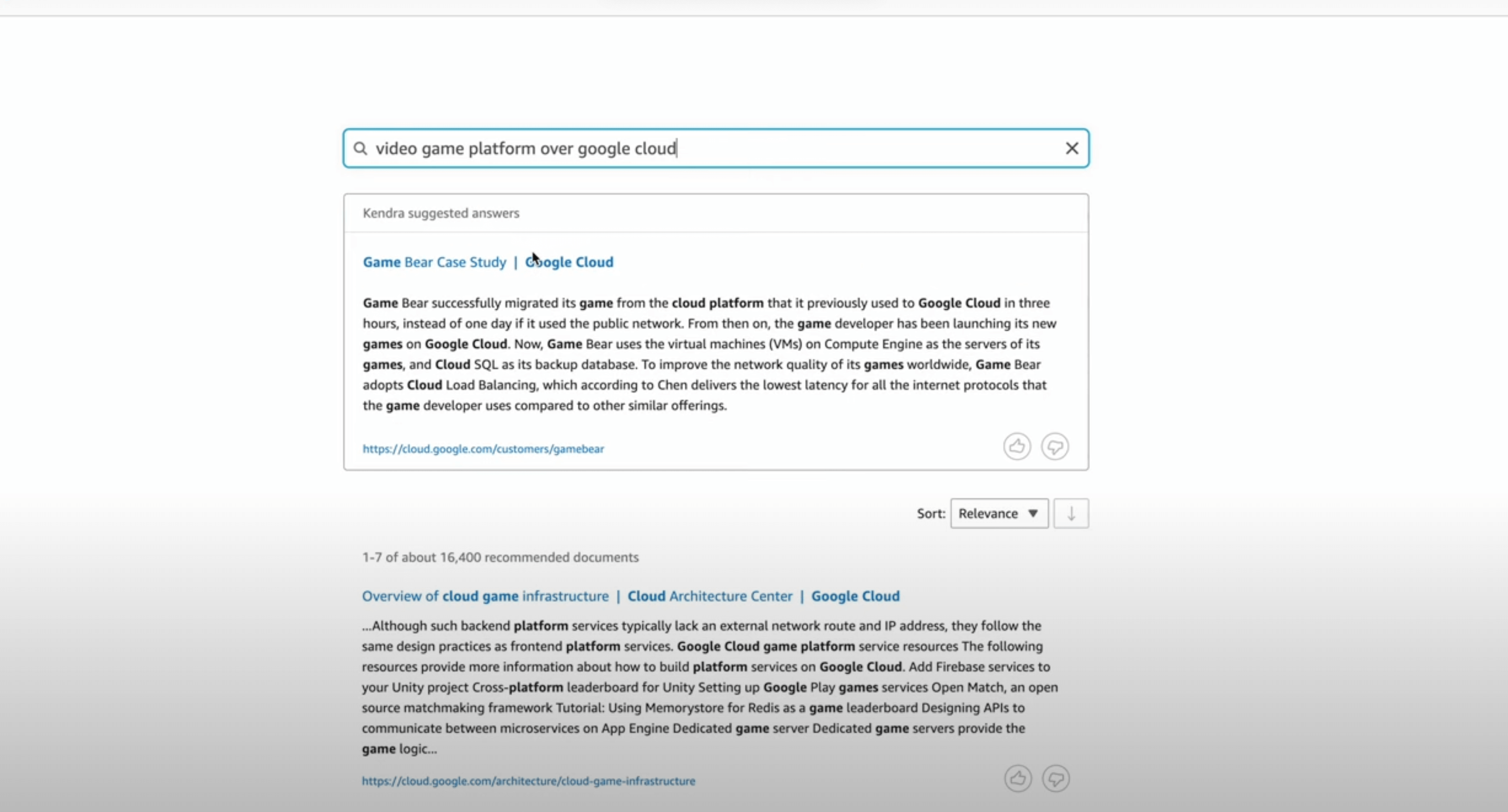
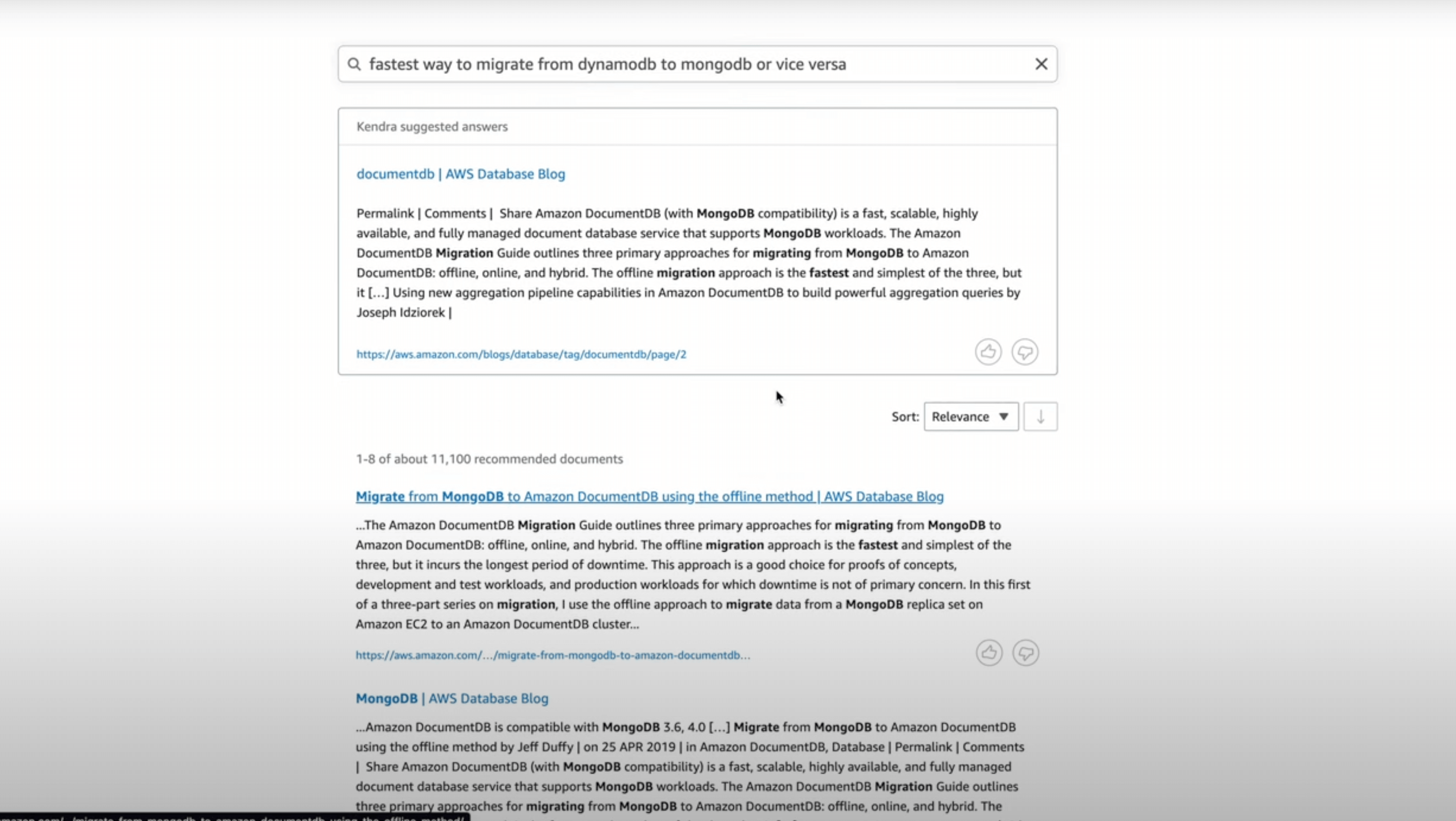
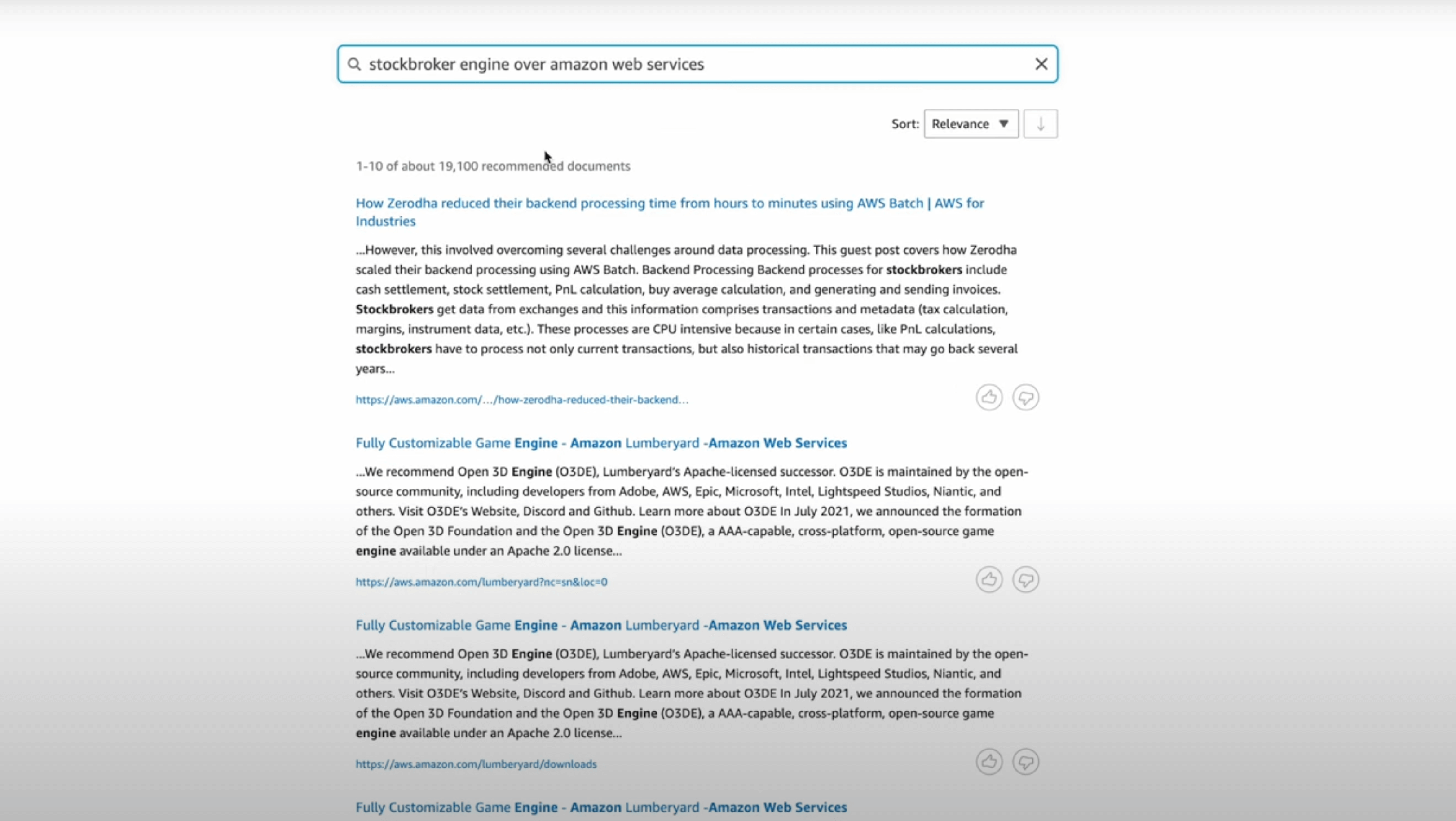
Part 2: "Generate"
Alright so you've got the top 10 documents you're supposed to refer to. But how can we improve the experience of gleaning valuable insights for your given business problem? That's where we use the superpower of an LLM. It's like asking it to read all documents and answer over it
So, once we "retrieve" the documents from Amazøn Kendra, we ask the LLM to take the top 5 most relevant documents, pass all the text in them as tokens to the LLM (number of tokens varies depending on the LLM, we used GPT-4 by OpenAI that takes in upto 8000 tokens). The LLM parses the text and via few-shot learning over the context of business problem and the documents from Kendra, "generates" a response for the end user.
This is the simple task. Get the relevant docs and then generate a textual response from the same. Let's improve the experience now.

Part 3: The end-to-end architecture
Stringing together this in an entire experience involved developing the following flow.
- Get the input prompt for the business requirement from the user and generate a set of relevant questions about the business to ask the user. For this we used an LLM

-
We recorded the question answers and the business requirement, did some text summarization and trimming (using
nltkto remove whitespaces, punctuations etc.) and then we pass it all as a cumulative context for searching best documents in Amazon Kendra -
Next, we get the best docuements from Amazon Kendra as text, combine that with business prompt and QnA and pass it to our LLM for giving a textual response
-
Once we get the response, we return that, along with hyperlinks to the documents that Kendra returned so the user can get our summarized,structured answer as well as refer the source documents for more information at their own leisure
-
To help the cloud engineer with more specific information, we added a feature to generate the following from the textual answer
6. Systems diagram for the architecture proposed to understand how to link together the building blocks
7. IaaC code template - Basically a CloudFormation code template to quickly just spin up the architecture and study its performance and behavior in cloud
8. Cost estimation - based on information that the LLM has been trained on, using AWS pricing docs as data source -
Lastly, we provided a chat interface for the user to keep passing more requirements (such as "make it cheaper?", "make the system faster?") to the service. Now, we pass a combination of these 4 things to the LLM to get an improved answer = original business prompt + QnA + generated answer + additional user request

What can we improve upon?
Here's the current complete system that was built:

Okay so this project was awesomely exciting but the main complaint I have from it is that it is too slow. It still takes 2 minutes to generate answers and diagrams. A way to improve that would be some compute on frontend or some level of caching
Also, the answers are still generic and unless the prompt is well-engineered, we wouldn't discover novel architectures and solutions. So, that's something we need to fine-tune for. Maybe some sort of a framework for the user to engineer their prompt even better. Asking better technical requirement questions for a given business prompt could be a good starting point.
Lastly, it's expensive. Kendra is expensive and so is using OpenAI. So the approach for solving this is - open-source it! A search index with Elasticsearch combined with a custom LLM such as the Llama, Lima and Flan-T5 models can help cut down on costs
Oooh, a cool feature could have also using voice to speech and language translation (with using localized cloud services docs) to provide multilingual support to our beloved copilot
In closing....
We're having a copilot for pretty much everything these days ever since the Generative AI hype cycle started so I just thought of creating something that could help engineers to better adopt the Cloud Services by any cloud and help leverage them in the best possible way
Here are some useful reference links:
Building a Retrieval Augmented System using an LLM
Indexing web documents using Amazon Kendra
Let's see how fast you get from 0 to cloud.
