

For the deployment of v4 of a project's backend setup - A Nest JS-Prisma-MongoDB Stack, I used AWS Data Migration Service that helped me create the object mappings between the 2 databases & easily transfer all the data seamlessly
What would have been 6 hours of documentation & writing a migration script, actually became 12 hours of figuring out how the heck does AWS DMS even work & hence, this blog is a collection of all the 30+ blogs, GitHub issues & Stack Overflow answers that led to this successful migration on Sept 15th, 2022
Here’s the UI of the AWS DMS Service as of Sept 15th 2022 and now I’m going to run through the basic steps followed to do this migration
Prepare the MongoDB cluster for migration
Here, I did nothing, except opening the DB to be network-accessed from anywhere and created an admin user whose credentials I could give to AWS DMS for the migration
Create the replication server
AWS DMS creates a replication instance in a virtual private cloud (VPC). Select a replication instance class that has sufficient storage and computing power to perform the migration task, as mentioned in the whitepaper
AWS Database Migration Service Best Practices.
Choose the Multi-AZ option for high availability and failover support using a Multi-AZ deployment, as shown in the following screenshot.
You can specify whether a replication instance uses a public or private IP address to connect to the source and target databases.
You can create one replication instance for migrating data from all shard source endpoints, or you can create one replication instance for each shard source endpoint. We recommend that you create one replication instance for each shard endpoint to achieve better performance when migrating large volumes of data.
Create the source MongoDB endpoint
Reference Link
- The following screenshot shows the creation of a source endpoint for the MongoDB database.
- Create one source endpoint for the primary replica of each shard. This step is required to migrate data from each shard individually.
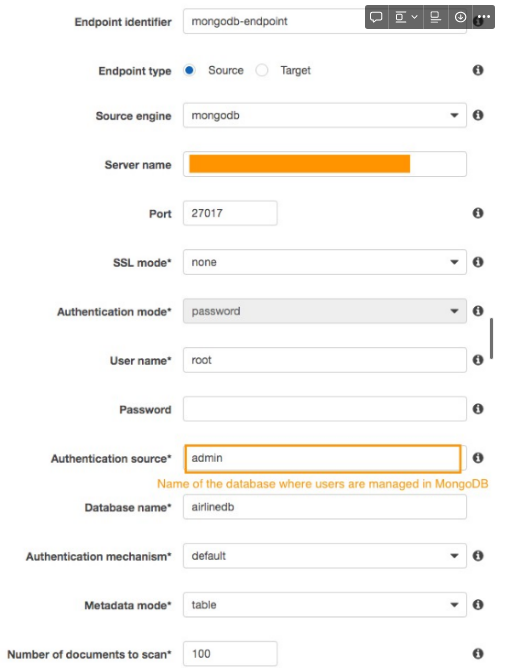
IMPORTANT - Ensure that you specify shard name as server_name while creating source endpoint. i.e. while mongodb actually tells you that the endpoint is CLUSTER_NAME.PREFIX.mongodb.net, the endpoints are actually of the form CLUSTER_NAME_SHARD_NAME_SHARD_NUM.mongodb.net. Use this python command to get the shard names & ports of each shard that you can use as an endpoint
# / SRC -> <https://www.mongodb.com/developer/products/mongodb/srv-connection-strings/>
import srvlookup # pip install srvlookup
import sys
import dns.resolver # pip install dnspython
host = None
if len(sys.argv) > 1:
host = sys.argv[1]
if host:
services = srvlookup.lookup("mongodb", domain=host)
for i in services:
print("%s:%i" % (i.hostname, i.port))
for txtrecord in dns.resolver.query(host, 'TXT'):
print("%s: %s" % (host, txtrecord))
else:
print("No host specified")
Ensure that you select SSL as require while making the source endpoint & authentication_mechanism is set to SCRAM_SHA_1
Here's a JSON file for the source endpoint - mongodb+srv://coursemapp:RANDOM_PASSWORD@CLUSTER_NAME.2g6bq.mongodb.net/coursemap-db?retryWrites=true&w=majority :
You can choose or choose not to mention db-name while setting up src endpoint. I tried both ways - both worked. In my case, the db-name, as evident from the mongo_connection_string above, was coursemap-db. Can even notice this in mongo db
{
"Username": "coursemapp",
"ServerName": "CLUSTER_NAME-shard-00-00.2g6bq.mongodb.net",
"Port": 27017,
"AuthType": "password",
"AuthMechanism": "scram-sha-1",
"NestingLevel": "one",
"ExtractDocId": "false",
"DocsToInvestigate": "100",
"AuthSource": "admin"
}
The following example shows the source endpoint for three shards:
Create the target DynamoDB endpoint
- The following screenshot shows the creation of a target endpoint for Amazon DynamoDB:
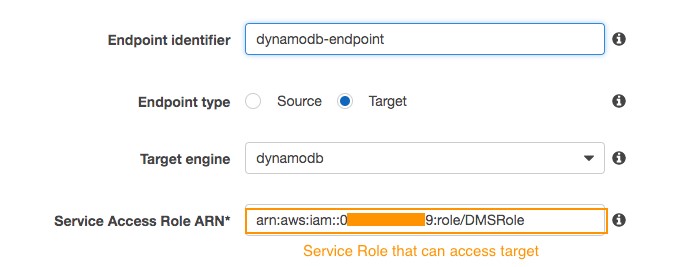
- AWS DMS creates a table on a DynamoDB target endpoint during the migration task execution and sets several DynamoDB default parameter values.
- Additionally, you can pre-create the DynamoDB table with the desired capacity optimized for your migration tasks and with the required primary key.
- You need to create an IAM service role for AWS DMS to assume, and then grant access to the DynamoDB tables that are being migrated into.
Create tasks with a table mapping rule
Both MongoDB and Amazon DynamoDB allow you to store JSON data with a dynamic schema.
DynamoDB requires a unique primary key—either a partition key or a combination of a partition and a sort key. You need to restructure the fields to create the desired primary key structure in DynamoDB.
The partition key should be decided based on data ingestion and access patterns.
As a best practice, we recommend that you use high-cardinality attributes (attribute having high number of unique/distinct values) . For more information about how to choose the right DynamoDB partition key, refer to the blog post Choosing the Right DynamoDB Partition Key.
Based on the example query patterns described in this post, we recommend that you use a composite primary key for the target DynamoDB table.
The following screenshot shows the attribute mapping between MongoDB and DynamoDB
For a sharded collection, MongoDB distributes documents across shards using the shard key. To migrate a sharded collection to DynamoDB, you need to create one task for each MongoDB shard.
Create an AWS DMS migration task by choosing the following options in the AWS DMS console for each shard endpoint:
- Specify the Replication instance.
- Specify the Source endpoint and Target endpoint.
- For Migration type, choose Migrate existing data and replicate ongoing changes to capture changes to the source MongoDB database that occur while the data is being migrated.
- Choose Start task on create to start the migration task immediately.
- For Target table preparation mode, choose Do nothing so that existing data and metadata of the target DynamoDB table are not affected.
- If the target DynamoDB table does not exist, the migration task creates a new table; otherwise, it appends data to an existing table.
- Choose Enable logging to track and debug the migration task.
- For Table mappings, choose Enable JSON editing for table mapping.
The following screenshot shows these settings on the Create task page in the console:

Used the object-mapping functionality in AWS DMS. 2 types of rules against wildcard matched entities can be specified here
selectionrules -> Link - to just select which all tables you want from src dbtransformationrules -> Link- Each of these rules is applied on tables whose names you can enter manually, or pattern match them - Link - to select which tables you want from src db + transform (eg : rename, change data type, make composite attributes) certain attributes/columns while the migrations are happening
- Here's the
object-mappingrule set I used (to get all the mongo tables into ddb) without any transformation
{
"rules": [
{
"rule-type": "selection",
"rule-id": "213057977",
"rule-name": "213057977",
"object-locator": {
"schema-name": "%",
"table-name": "%"
},
"rule-action": "include",
"filters": []
}
]
}
You can also choose to create something called a "pre-migration assessment report" in DMS, that just tests all the connections & other things, before the data migration starts. Is useful and this option appears when you're about to create a data migration task
Table mappings in Create task

AWS DMS uses table mapping rules to map data from a MongoDB source to Amazon DynamoDB. To map data to DynamoDB, you use a type of table mapping rule called object mapping.
For DynamoDB, AWS DMS supports only map-record-to-record and map-record-to-document as two valid options for rule-action.
For more information about object mapping, see Using an DynamoDB Database as a Target for AWS Database Migration Service.
In our example, we set the object mapping rule action as **map-record-to-record** while creating the AWS DMS task. The map-record-to-record rule action creates an attribute in DynamoDB for each column in the source MongoDB.
AWS DMS automatically creates the DynamoDB table (if it’s not created already), the partition key, and the sort key, and excludes any attributes based on the object mapping rule.
The following table mapping JSON has two rules.
- The first rule has a rule type as selection, for selecting and identifying object locators in MongoDB.
- The second rule has a rule type as object mapping, which specifies the target table-name, definition, and mapping of the partition key and sort key.
For more information about the object mapping for DynamoDB, see Using Object Mapping to Migrate Data to DynamoDB.
The following image shows migration tasks for three shards (corresponding to three source endpoints that were created in the previous step) :
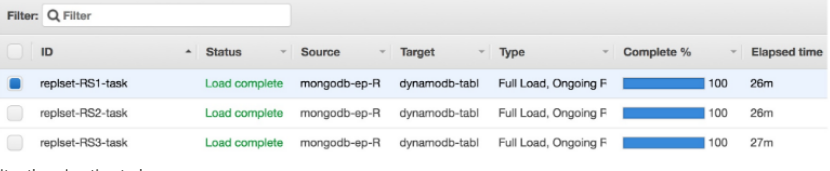
Monitor the migration tasks
The AWS DMS task can be started immediately or manually depending on the task definition.
The AWS DMS task creates the table in Amazon DynamoDB with the necessary metadata, if it doesn’t already exist. You can monitor the progress of the AWS DMS task using Amazon CloudWatch , as shown in the following screenshot. For more information, see Monitoring AWS Database Migration Service Tasks
You can also monitor the AWS DMS task using control tables, which can provide useful statistics. You can use these statistics to plan and manage the current or future tasks. You can enable control table settings using the Advanced settings link on the Create task page. For more information, see Control Table Task Settings
The following screenshot shows the log events and errors captured by CloudWatch:
Problems faced
During this migration, the list types from MongoDB got stored as plain strings in DynamoDB & this became a huge problem since the data was corrupt.
For eg. {prerequisites: ["p1", "p2"] } in MongoDB was stored as { prerequisites: "["p1","p2"]"} in DynamoDB.
This was solved by using a piece of code that migrates the data from 1 dynamodb table to another and modifies the data while in-transit
// The approach for this process would be to create a temporary "Full DDB access" credential
// and use it to actually migrate the data across tables & delete the credentials after
// reason being : we can't trust the package with such an important IAM credential for our AWS account
var copy = require('copy-dynamodb-table').copy
var globalAWSConfig = { // AWS Configuration object <http://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/Config.html#constructor-property>
accessKeyId: 'ACCESS_KEY_ID',
secretAccessKey: 'ACCESS_KEY_SECRET',
region: 'ap-south-1'
}
const convertStringToArray = (string) => {
return string.replace(/['"\\[\\]]+/g,"").split(',').map((item) => item.trim()).filter(item => item.length>0)
}
// For courses
const courseDtoConverter = (item) => {
const dtoItem = {
id: item.oid__id,
courseContent: convertStringToArray(item.array_courseContent),
prerequisites: convertStringToArray(item.array_prerequisites),
referenceBooks: convertStringToArray(item.array_referenceBooks),
textBooks: convertStringToArray(item.array_textBooks),
courseCode: item.courseCode,
courseType: item.courseType ?? "Theory",
credits: item.credits,
deptCode: item.deptCode,
description: item.description ?? "",
name: item.name
}
console.log(dtoItem)
return dtoItem;
}
const transferData = (srcTableName, destTableName, dtoConverter) => {
copy({
config: globalAWSConfig, // config for AWS
source: {
tableName: srcTableName, // required
},
destination: {
tableName: destTableName, // required
},
log: true, // default false
// create : true, // create destination table if not exist
schemaOnly : false, // if true it will copy schema only -- optional
continuousBackups: true, // if true will enable point in time backups
transform: function (item, index) {
return dtoConverter(item);
} // function to transform data
},
function (err, result) {
if (err) {
console.log(err)
}
console.log(result)
})
}
// For copying "courses" table
transferData("SRC_TABLE_IN_DYNAMODB",'DEST_TABLE_IN_DYNAMODB', courseDtoConverter)
