

In the realm of natural language processing, optimizing large language models (LLMs) is a formidable challenge. Striking the delicate balance between performance and efficiency is akin to finding a needle in a haystack of computational complexity. The performance of LLMs, often abstract and difficult to measure, requires a nuanced approach to optimization. In this blog, we’ll explore a mental model of options for LLM optimization and develop an appreciation for which option to use and when.
You will leave with a foundational understanding of the two axes of optimization—context and LLM behavior—as well as a practical guide to the nuanced world of model refinement.
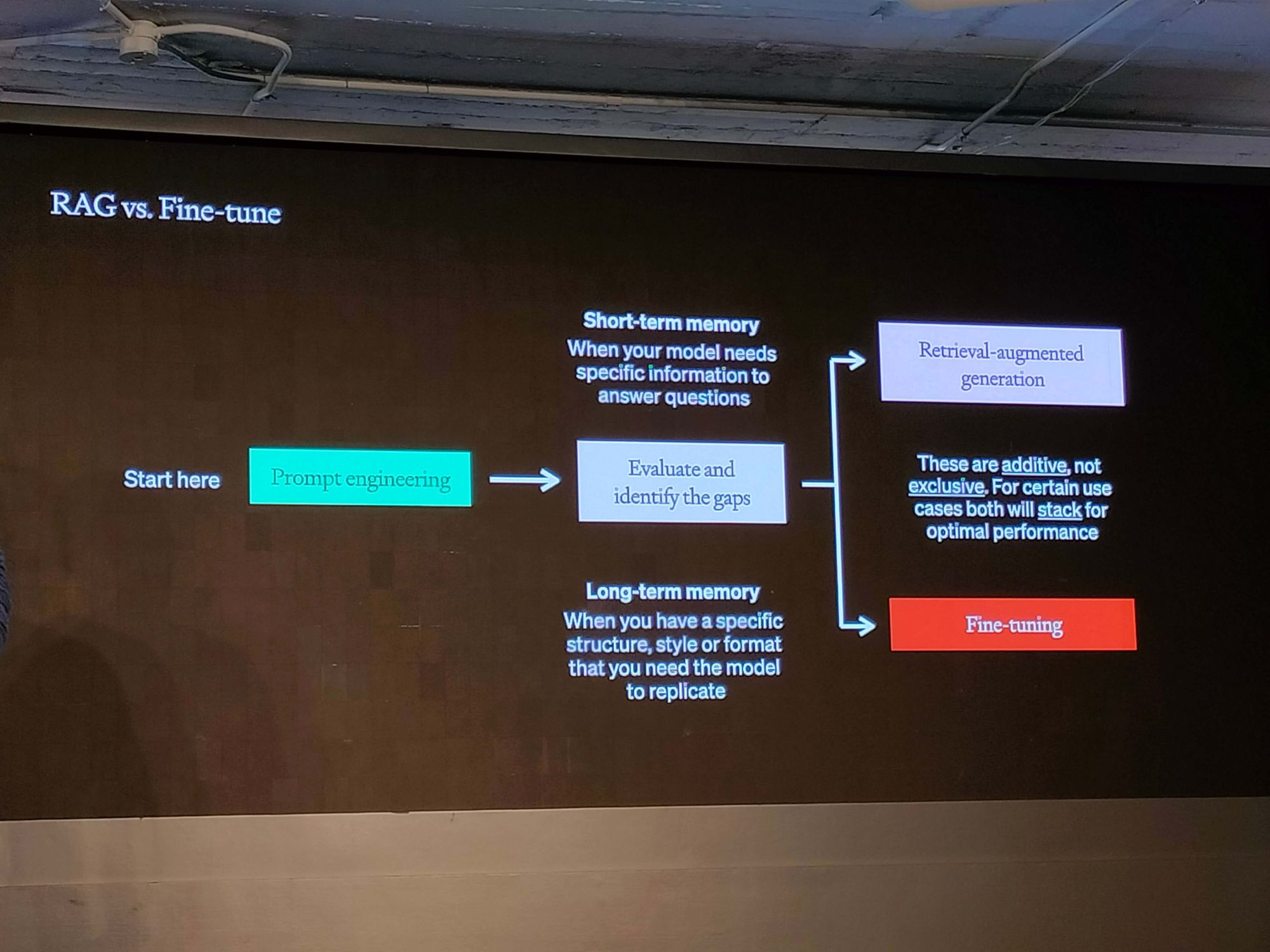
The Twin Axes of Optimization

1. Context Optimization
At its core, context optimization is about fine-tuning what the model needs to know. Here’s how you can approach it:
- Prompt Engineering: As the lower-left quadrant in our optimization matrix, prompt engineering is your fast lane to setting a baseline. Start by refining the prompts you feed into the LLM and observe the performance changes.
- Retrieval Augmented Generation (RAG): Positioned in the upper-left, RAG introduces more context. Begin with simple retrieval mechanisms, and consider fine-tuning for a more nuanced approach.
2. LLM Behavior Optimization
LLM behavior optimization delves into how the model should act. The two main strategies are:
- Fine-tuning: The lower-right quadrant represents fine-tuning, which customizes the LLM’s behavior for specific tasks.
- Comprehensive Approach: Sometimes, a combination of all methods is required to reach the desired performance level. An example would be integrating HyDE retrieval with a fact-checking step.
The key is to start somewhere, evaluate, and then iterate with another method.
Strategies Explored
Prompt Engineering: The Starting Block
Starting with clear, concise instructions and breaking down complex tasks into simpler subtasks is paramount. Giving models "time to think" and testing changes systematically can yield surprising improvements. Extending this by providing reference text and using external tools can further enhance the results.

When It Shines:
- Quick testing and learning
- Establishing a baseline for further optimization
Its Limitations:
- Introducing new information
- Replicating complex styles or methodologies
Retrieval Augmented Generation: Expanding Knowledge
By giving LLMs access to domain-specific content, RAG helps update the model's knowledge and control the content it generates to reduce inaccuracies.
When It Shines:
- Introducing new, specific information
- Controlling content to reduce errors
Its Limitations:
- Broad domain understanding
- Learning new languages, formats, or styles
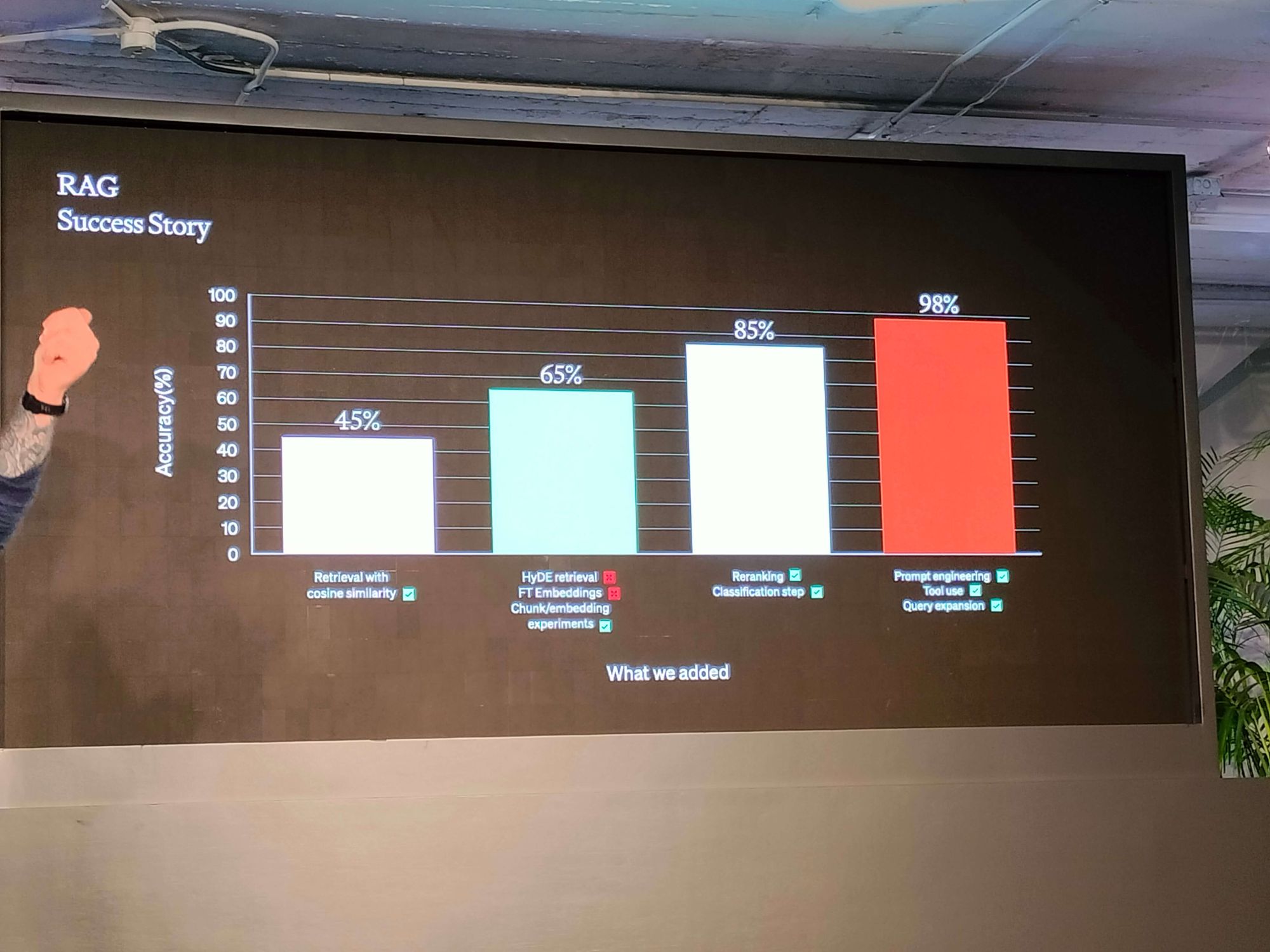
Enhancing RAG:
- Employ retrieval with cosine similarity and HyDE
- Experiment with FT embeddings and chunking
- Implement reranking and classification steps
Evaluating RAG:
- On the LLM side, consider the faithfulness and relevance of the answers.
- On the content side, assess the precision and recall of the context retrieved. More data does not necessarily equate to higher accuracy.

Fine-tuning: The Custom Tailor
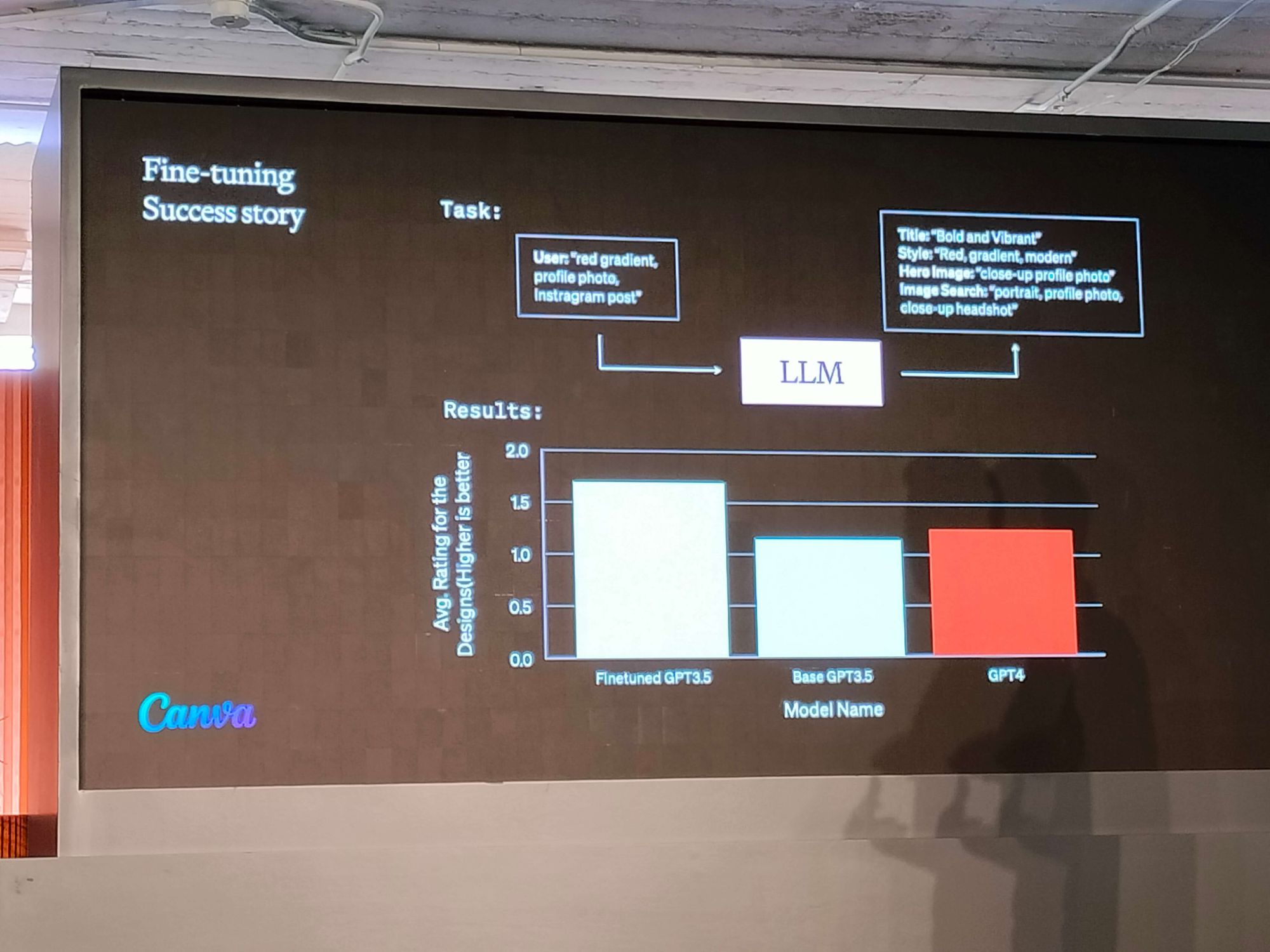
When prompt engineering doesn't cut it, fine-tuning may be the right path. Continuing the training process with domain-specific data can optimize model performance and efficiency. For example, Canva leveraged fine-tuned GPT-3.5 to produce structured output, showcasing the power of high-quality training data.

When It Shines:
- Emphasizing existing knowledge
- Customizing response structure or tone
Its Limitations:
- Injecting new knowledge into the model
- Quick iterations on new use-cases
Steps to Fine-tune:
- Data preparation
- Hyperparameter selection and loss function understanding during training
- Evaluation with relevant test sets and expert opinion
Fine-tuning Best Practices:
- Start with prompt engineering
- Establish a clear baseline
- Prioritize quality over quantity in training data
The Combined Approach: Fine-tuning + RAG
Sometimes, a blend of fine-tuning and RAG yields the best results. This method allows the model to understand complex instructions with minimal tokens, creating more space for retrieved context and leading to a more robust performance.
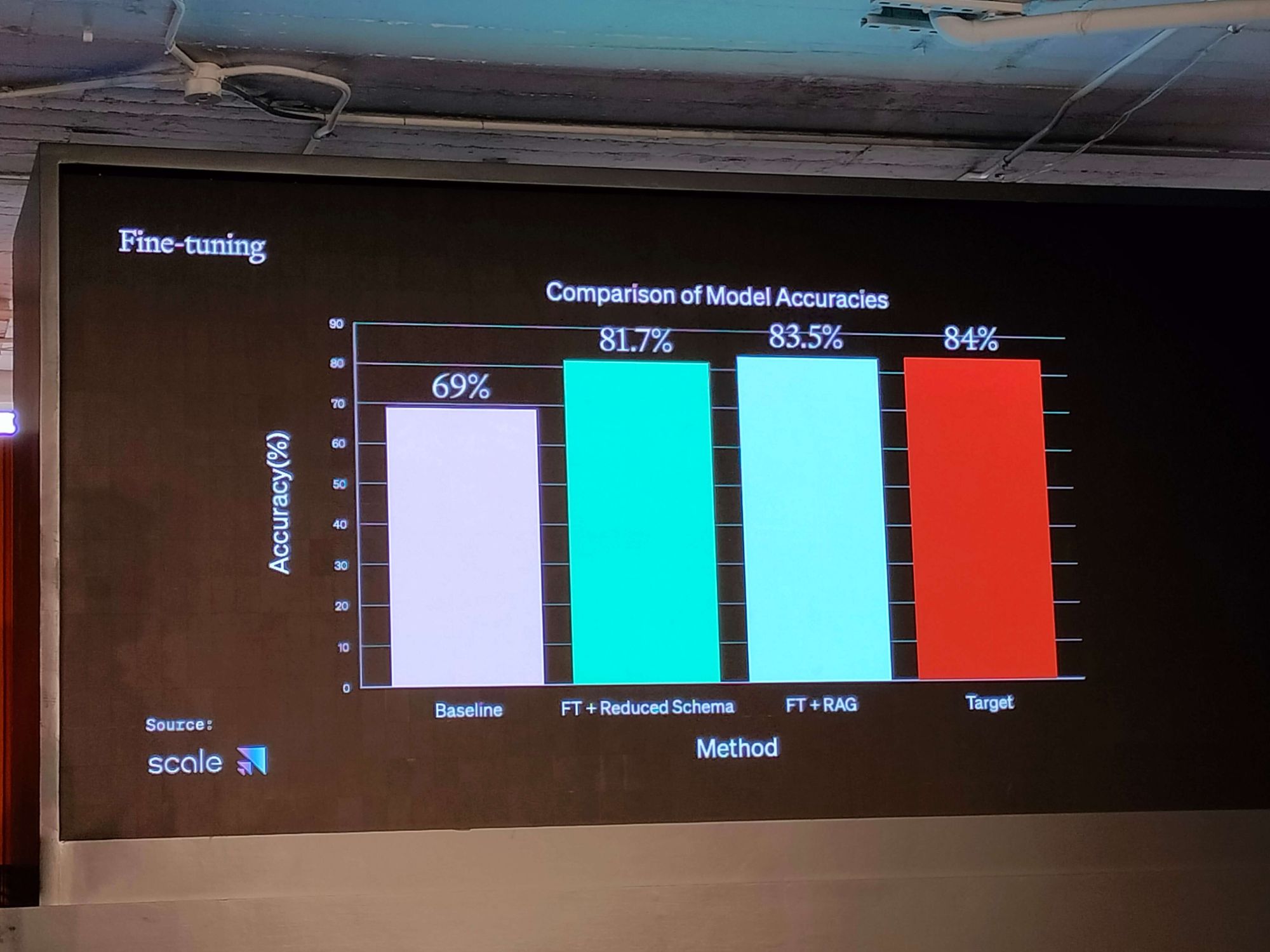

Practical Application
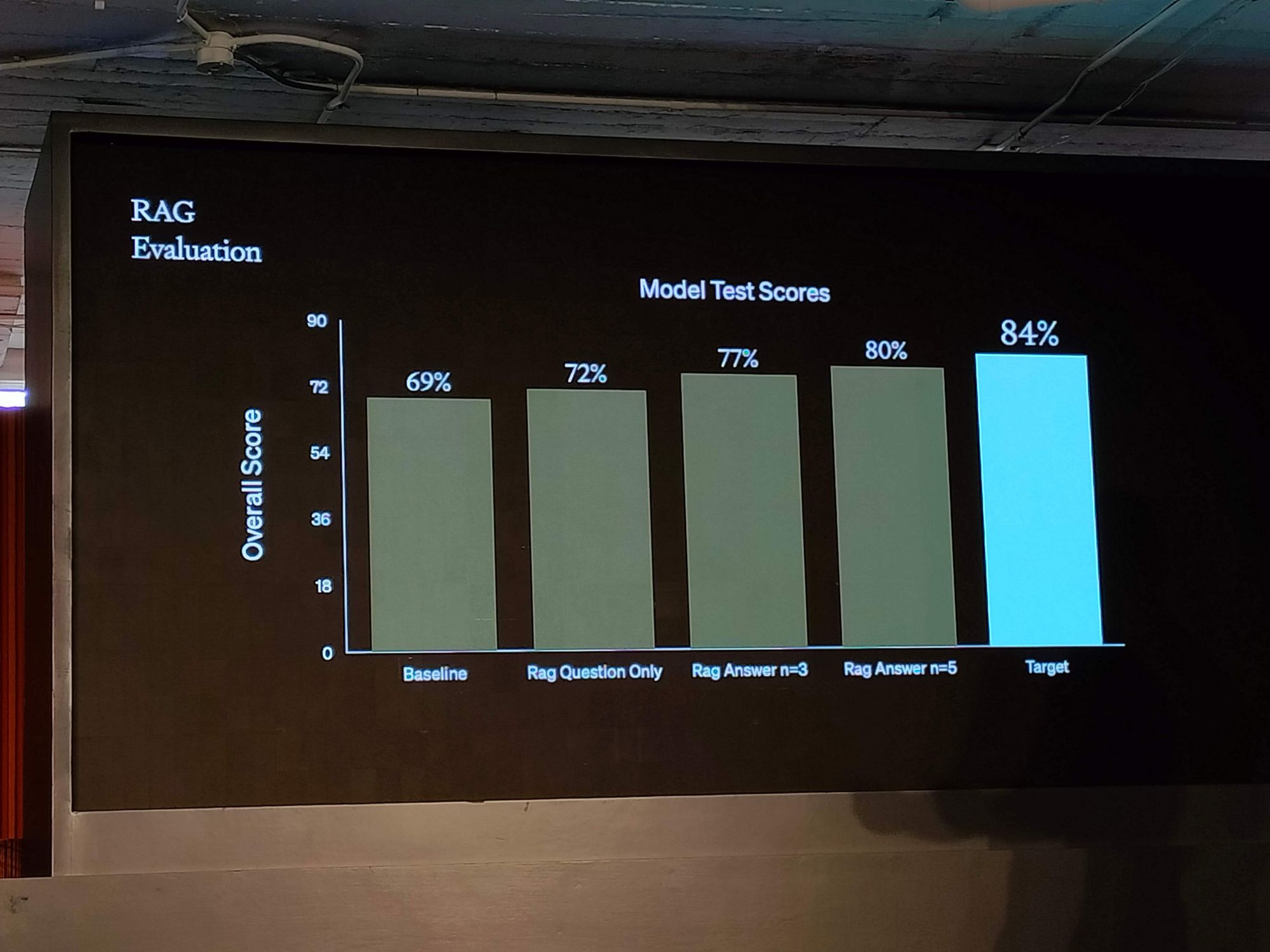
The real-world application of these strategies can be as creative as generating hypothetical answers to enhance similarity searches. For example, initial baselines might yield a 69% performance rate, while a RAG with a well-crafted answer could increase that to 84%, comparable to fine-tuning. Collaborations, such as the one between Scale AI and OpenAI, demonstrate how a combined approach can optimize models to new heights of efficiency and effectiveness.

In conclusion, maximizing LLM performance isn’t a one-size-fits-all endeavor. It requires a toolkit of strategies—from prompt engineering to fine-tuning and beyond—each with its own set of benefits and best-use scenarios.
